





产品分享社区
声明:网站上的服务均为第三方提供,请用户注意甄别服务质量
在大规模数据采集(Web Scraping)任务中,IP 被封禁是所有出海与数据团队的头号噩梦。步入 2026 年,以 Cloudflare、Akamai 为代表的防爬风控系统全面升级,从传统的“看访问频率”演变为“基于行为、协议与全套浏览器指纹”的立体式审查。
本文将结合网络底层技术经验,为你深度拆解 2026 大规模抓取任务中,IP 被封禁的底层逻辑、识别标志、自救自查路径,以及6个实测有效的修复与预防方案。
IP封禁是指目标网站的反爬虫系统一旦发现某个 IP 的请求特征异常,就会在网关或 WAF(Web 应用防火墙)层面对该 IP 采取限制措施,服务器会直接丢弃或拒绝来自该IP的任何连接请求。
根据封禁的严重程度和持续时间,IP封禁可以分为两类:
判断技巧:如果封禁在一天内解除,很可能是临时的;如果超过72小时仍无变化,建议视为永久封禁并更换IP。
1.发送请求过多过快(触发 Rate Limiting): 单 IP 在 1 秒内发送了几十甚至上百次请求,这严重超出了人类的浏览极限,会瞬间触发目标站点的速率限制阀值。
2.违反服务条款(ToS): 高并发抓取某些需要登录的、涉及用户隐私或版权的核心商业数据(如社交媒体私密帖子、电商全量价格变动),极易触发高阶风控。
3.忽视 robots.txt 规则: 很多商业网站会在 robots.txt 中明确禁止爬虫访问特定目录,或者指定了 Crawl-delay(抓取延迟)。完全无视规则强行进入,会被反爬系统重点标记。
4.触发浏览器指纹特征(Browser Fingerprinting): 这是 2026 年最主流的封禁原因。 即使你用了代理,但如果你的无头浏览器(Headless Browser)暴露了 navigator.webdriver = true,或者 Canvas 指纹、TLS/JA4 指纹、HTTP/2 协议特征与普通的 Chrome 浏览器不匹配,就会被秒封。
5.频繁卡验证码(CAPTCHA): 当反爬系统拿不准时会弹出一个 Cloudflare Turnstile 或 Google reCAPTCHA 验证码。如果你的自动化脚本无法处理,或者破解脚本频繁失败,该 IP 会直接被判定为恶意 Bot 并执行封禁。
在 2026 年,目标网站为了节省带宽和迷惑爬虫,往往不会大方地弹出一个带有“You are banned”的网页,而是采用更隐蔽的策略:
| 表现特征 | 背后潜台词(风控逻辑) |
| HTTP 403 Forbidden | 最直接的拒绝。服务器明确知道你是谁,但拒绝为你提供服务。 |
| HTTP 503 Service Unavailable | 表面上是服务器过载,实际是 WAF 在网关层对你的 IP 执行了流量清洗。 |
| 连接超时(Timeouts) | 目标服务器直接丢弃(Drop)来自你 IP 的所有 TCP 握手包,让你的程序无限处于等待状态直至崩溃。 |
| 隐蔽的空白页(软封禁) | 状态码返回普通的 200 OK,但 HTML 页面里没有任何实际数据,或者全是随机生成的乱码(“喂假数据”)。 |
| 无限验证码循环 | 无论你的自动化脚本如何绕过或通过验证码,刷新后依然无限弹出新的验证码。 |
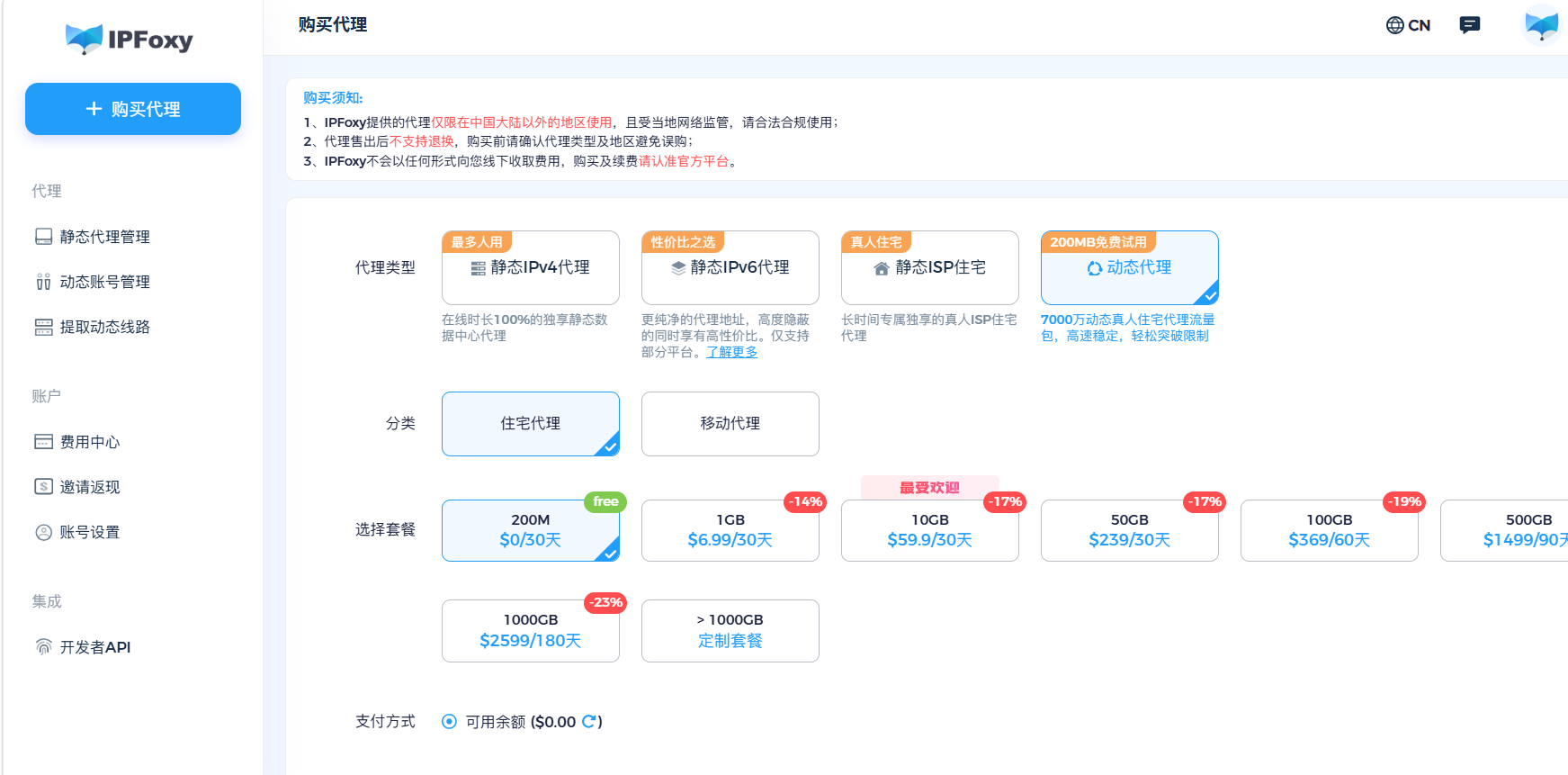
这是最直接、最有效的方法。IP地址就是你的网络门牌号,当它被拉黑,换一个全新的、干净的地址是最快的解决办法。
数据中心代理如果被大面积封禁,说明该机房段已被大厂风控拉黑,优先选择高质量住宅ISP代理。住宅IP来自真实家庭宽带网络,在目标网站看来就像一个普通家庭用户在访问,可信度极高。
切换到高质量的住宅代理服务可以从根本上降低被封概率。有实测数据显示,在尝试多个代理服务失败后,转向住宅网络代理,72小时内成功率可从61%提升至95%。比如IPFoxy提供的代理服务,囊括住宅代理、ISP代理、移动代理类型,均为纯净无滥用的IP资源,真实干净的特性可以帮助提高脚本任务可信度。
这是很多人忽略但非常关键的一步。浏览器本地存储了大量缓存文件、Cookie和本地存储数据,其中可能包含之前被封锁的会话信息和账号登录状态。即使更换了IP,如果带着旧的Cookie访问,服务器仍可能立刻识别出来。
建议在开始新的访问前彻底清理浏览器数据,使用浏览器的“无痕模式”,或使用具备隔离环境的浏览器工具。
许多封禁源于请求头信息缺失或异常。网站会通过检查User-Agent、Accept-Language、Referer等头部信息来识别自动化请求。
操作建议:
如果确定是临时封禁,最省力的办法就是等待。临时封禁通常在几小时到72小时内自动解除。建议利用等待时间分析被封原因,优化爬虫策略,避免重新上线后再次被封。
仅仅更换IP有时还不够。如果浏览器指纹与你更换后的IP所在地区不匹配,仍然可能被识别出来。
建议使用支持指纹管理的浏览器工具,预设一套与当前IP地区相符的指纹配置文件,并集成在第一点提到的代理服务。禁用WebRTC防止暴露真实IP,修改Navigator对象删除webdriver标识,伪装Canvas和WebGL的渲染结果。
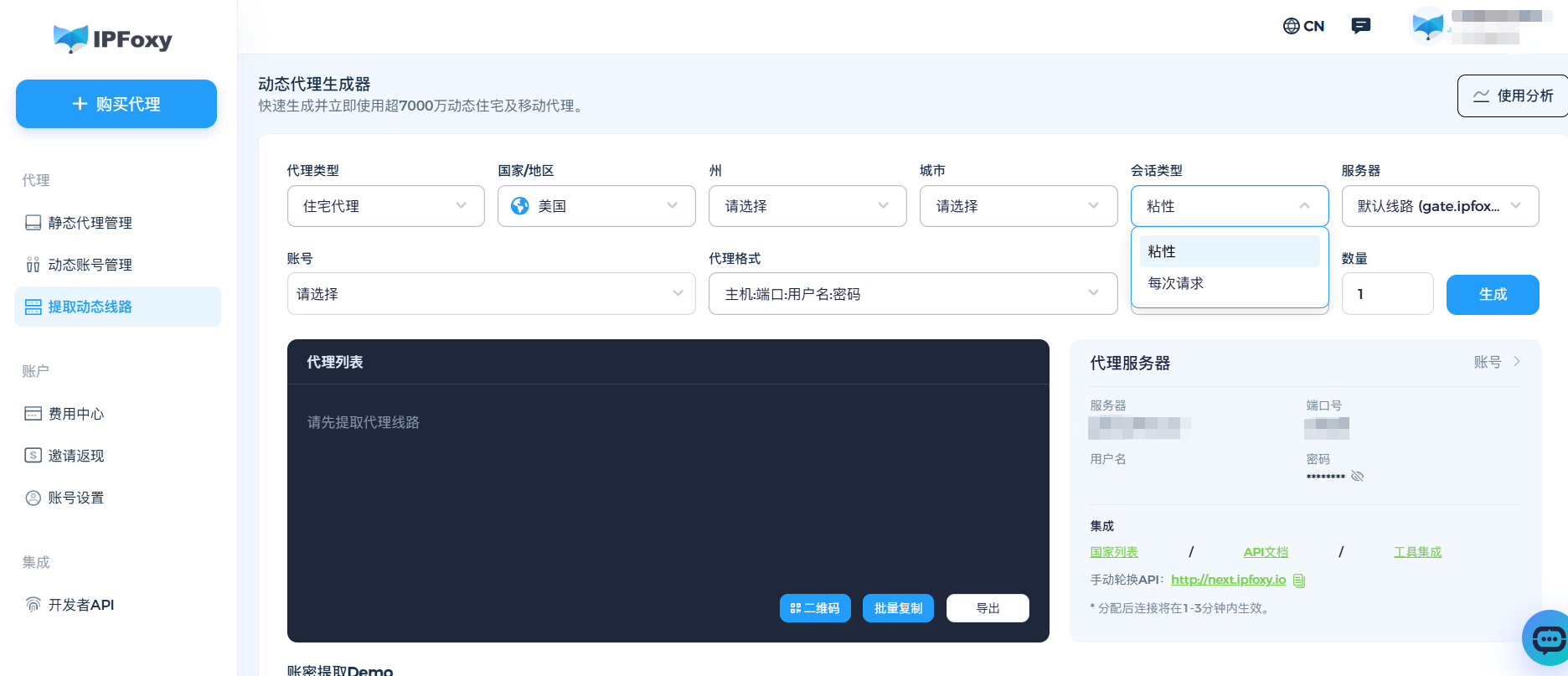
对于大规模持续采集任务,单一IP无论多么“干净”都难逃被封的命运。核心思路是建立代理IP池,让系统自动获取、切换、验证IP。
操作建议:
IPFoxy的动态住宅代理采用流量计费方式,支持IP自动按需设置轮换间隔,适合数据采集、价格监控和广告验证等场景,系统会自动基于实时网络状况自动分配至延迟最低的节点。
与其等IP被封再救,不如从源头做好预防。以下是2026年最有效的预防策略:
将动态代理IP池集成到爬虫框架中,让系统自动获取、切换、验证IP。建议引入多家不同供应商的IP并实现自动切换,选择支持API接入的代理供应商,在大量高并发的任务中可以更高效的完成动态代理的使用与切换。
在请求之间添加随机延迟,避免固定频率。规律的时间间隔是爬虫行为最核心的特征之一。可以这样实现:
python
import random, timetime.sleep(random.uniform(1, 3)) # 1-3秒随机延迟
每秒访问1-2次即可,不要太频繁。
2026 年,大厂对 TLS 握手特征(JA3/JA4 指纹)和 H2/H3 协议特征的审查极为严格。
如果使用 Python,可以使用 curl_cffi 或 tls-client 库来代替传统的 requests,它们能完美模拟 Chrome 的底层 TLS 握手特征。
如果需要渲染 JavaScript,可以利用高级指纹浏览器(Anti-detect Browser)开放的自动化接口(如 Puppeteer/Playwright 连接本地指纹浏览器环境),配合 代理实现深度伪装。
IP封禁是大规模抓取任务中不可避免的挑战,但通过系统性的策略——从理解封禁机制、快速自救恢复到建立长效预防体系——完全可以将影响降到最低。关键在于用对工具、用对方法、用对策略。
 微信公众号
微信公众号