





产品分享社区
声明:网站上的服务均为第三方提供,请用户注意甄别服务质量
在跨境电商竞争日益激烈的今天,数据已经成为卖家选品调研、价格监控、竞品分析和市场洞察的重要依据。作为全球最大的独立站生态之一,Shopify 聚集了数百万商家,其商品页面中蕴含着丰富的商业数据和市场信息。
然而,随着网站结构日益复杂和反爬机制不断升级,传统爬虫的开发与维护成本越来越高,AI 网页抓取正逐渐成为主流方案。借助大语言模型(LLM)、自动化浏览器和代理网络,企业能够更高效地完成 Shopify 商品数据采集。本文将带你了解如何利用 AI 搭建一套稳定、高效的 Shopify 数据抓取流程。
随着 AI 技术的发展,网页数据采集正从“规则驱动”走向“理解驱动”。相比依赖 XPath 和 CSS Selector 的传统爬虫,AI 能够直接理解页面内容,自动识别商品名称、价格、SKU 等关键信息,即使页面布局调整,也能保持较好的适应能力,从而提升采集效率并降低维护成本。
| 对比维度 | 传统网页抓取 | AI 网页抓取 |
| 数据提取方式 | 依赖固定规则 | 基于语义理解 |
| 页面改版适应能力 | 较弱 | 较强 |
| 动态页面处理 | 需要额外开发 | 更容易适配 |
| 维护成本 | 较高 | 相对较低 |
| 开发门槛 | 需要编程经验 | AI辅助开发 |
| 数据清洗能力 | 依赖人工规则 | 可自动结构化 |
对于跨境电商、市场研究和数据分析团队而言,AI 网页抓取不仅仅是一种新的技术工具,更是一种提升数据获取效率的新方式。

在过去,抓取 Shopify 数据通常需要手动编写爬虫、分析 DOM 结构,并投入大量精力维护解析规则。步入 2026 年,AI 已经能够贯穿代码生成、页面语义分析到数据结构化输出的全流程,大幅降低了跨境电商团队的数据采集门槛。
过去开发爬虫需要处理复杂的请求逻辑和异常机制。现在,通过 Claude Code、Cursor 或 ChatGPT 等 AI 编程助手,你只需输入业务需求,AI 就能在几秒钟内自动生成包含浏览器初始化、并发控制和异常处理的标准化基础框架,将项目开发周期缩短数倍。

在部署高成本的浏览器自动化方案之前,严谨的策略应当优先检查目标店铺是否开放了原生的商品 JSON 接口。多数 Shopify 店铺默认开放该接口,只需在域名后拼接 /products.json 即可尝试获取数据。
数据维度:可直接获取商品标题、详情描述、多规格 SKU、定价、划线价及高清图片 URL。
核心优势:相比解析 HTML 页面,调用接口不需要加载冗余的前端样式与脚本,请求效率更高、数据结构更完整、且不受前端改版干扰。
| 评估维度 | 传统 HTML 页面解析 | 优先调用 JSON 接口 |
| 请求效率 | 较低(需加载网页 DOM、样式及脚本文件) | 极高(仅传输纯文本的轻量级 JSON 报文) |
| 数据完整度 | 中等(部分隐藏的变体数据难以通过前端直接捕获) | 完整(可直接获取后台输出的完整属性字段) |
| 解析稳定性 | 易受前端主题改版、CSS 类名变更的干扰 | 高(核心 API 数据结构由 Shopify 官方统一维护) |
| 合规与负载 | 易因高频加载多媒体资源对目标服务器造成带宽压力 | 对服务器负载较低,策略更为温和 |
并非所有 Shopify 商家都会开放完整接口。一些品牌站会关闭 JSON 访问,或者通过 JavaScript 动态渲染商品内容,此时就需要借助 Playwright 模拟真实用户访问网页。
通过 AI 编写的 Playwright 脚本可以实现以下高级仿真行为:
(1)模拟真实用户的浏览轨迹,包括鼠标随机平滑移动、视口延迟滚动与页面停留。
(2)触发特定的页面交互(如点击变体组合、切换货币),确保获取到最终渲染完成的完整 DOM 节点。
风控对抗:针对 Cloudflare、DataDome 等顶级风控系统的高频拦截(如 403 或验证码),企业通常需要接入住宅代理网络(Residential Proxies)。通过轮换全球真实住宅 IP 模拟分布式访问,显著提升高防护站点的采集成功率。
完成页面访问后,采集到的通常是大量原始网页内容。相比传统爬虫依赖复杂的解析规则,AI 能够直接理解页面语义,并自动提取所需信息。
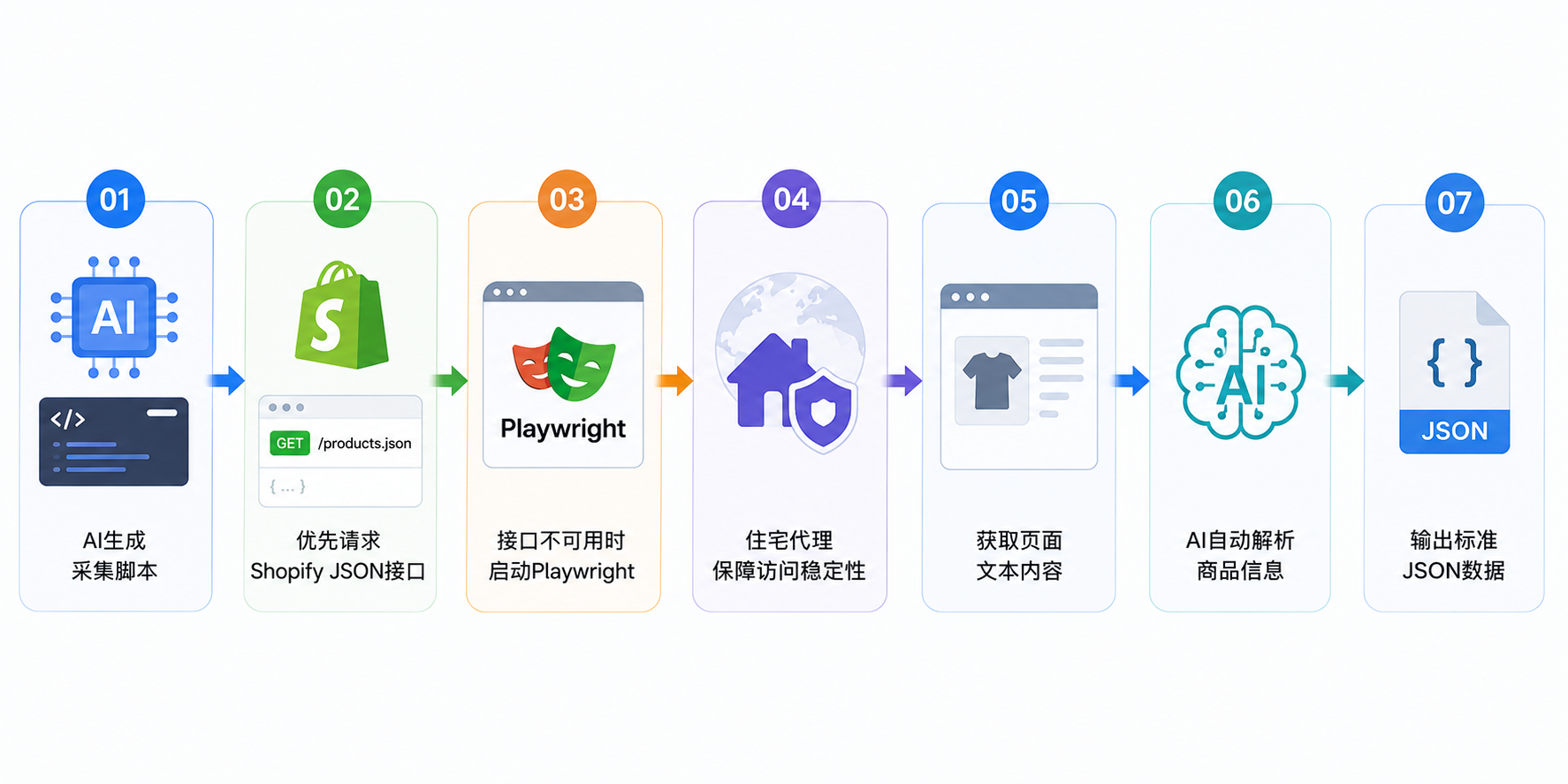
当采集规模从几个 Shopify 店铺扩大到数百甚至上千个站点时,仅仅能够成功抓取数据远远不够。此时需要同时兼顾采集效率、访问稳定性以及合规性,才能保证项目长期稳定运行。
AI 虽然能够大幅提升数据提取能力,但如果将完整网页内容全部提交给大模型解析,Token 消耗和处理成本也会随之增加。因此,在规模化采集过程中,需要合理控制 AI 的使用范围。
优化建议:
通过“规则筛选 + AI解析”的组合模式,通常能够在效率和成本之间取得更好的平衡。
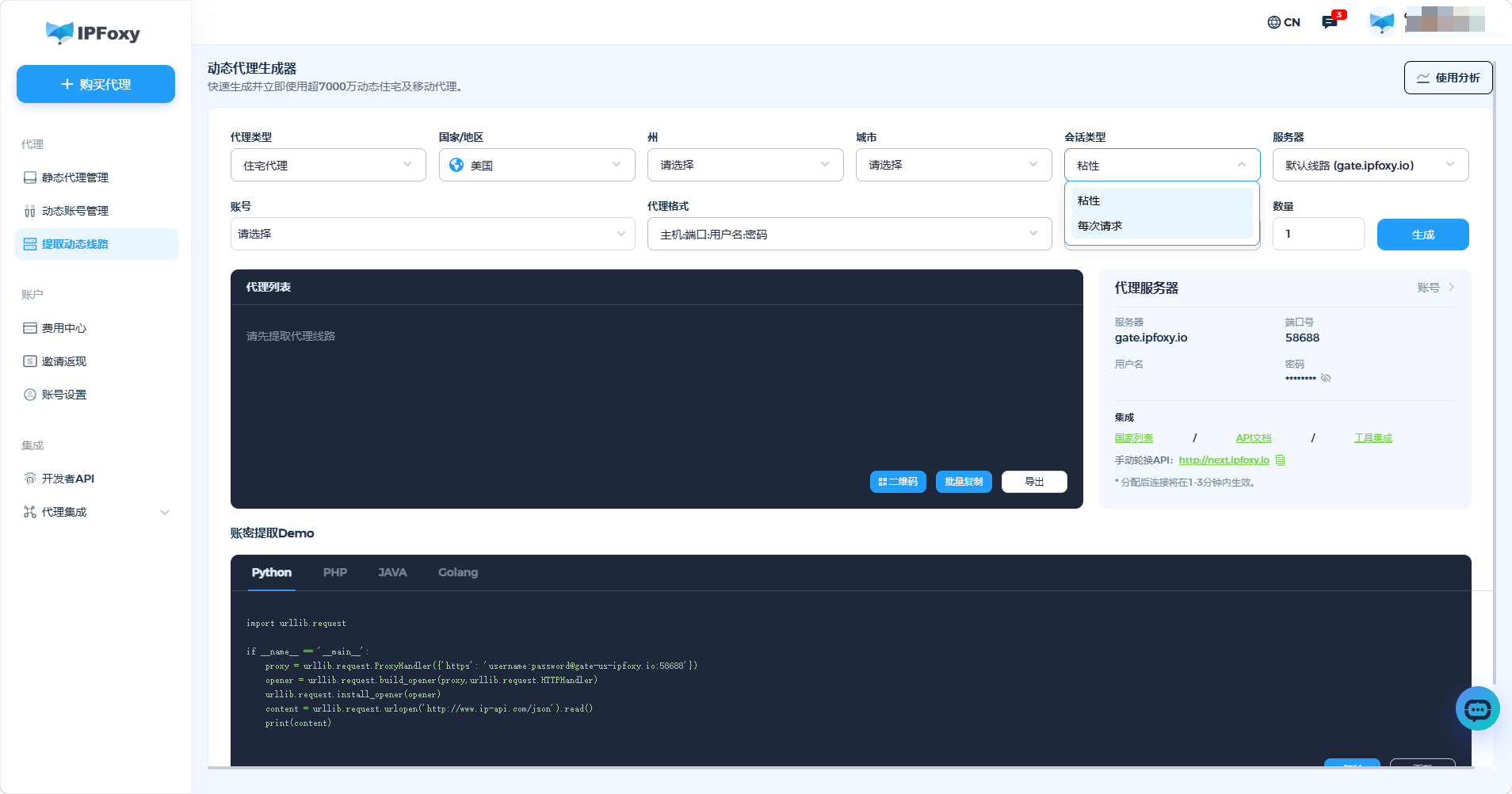
随着 Shopify 生态普遍接入 Cloudflare 等顶级风控,高频数据抓取极易撞上 403 Forbidden、验证码拦截或 IP 封禁。对于长期运行的 AI 抓取任务而言,稳定的网络环境往往比代码本身更重要。
对于专业的出海运营团队来说,通常会借助像 IPFoxy 等专业住宅代理服务,为 Playwright、Selenium 等自动化工具提供稳定的网络环境。在跨地区商品监控、价格追踪和竞品分析场景下,能够模拟更真实的用户访问行为,从而提高 Shopify 数据采集的成功率和稳定性。
无论采用传统爬虫还是 AI 网页抓取,都应遵循合理、规范的数据采集原则。稳定的数据项目不仅依赖技术能力,也离不开对目标网站规则的尊重。在保证合规性的前提下开展数据采集,才能更好地支撑长期的竞品监控和市场研究工作。
建议重点关注:
Q1:AI 抓取 Shopify 商品数据是否合法?
AI 抓取 Shopify 商品数据本身并不一定违法,但需要遵守目标网站的使用条款和相关法律法规。通常用于市场调研、竞品分析、价格监控等公开数据采集场景风险较低。建议控制抓取频率,避免对目标网站造成负载压力,并确保数据用于合法合规的商业分析用途。
Q2:Shopify 商品数据可以直接通过 API 获取吗?
很多 Shopify 店铺默认开放商品 JSON 接口,通常可以通过访问“域名/products.json”获取商品标题、价格、SKU、库存变体和图片等信息。如果接口未开放或数据经过动态渲染,则需要借助 Playwright 等浏览器自动化工具进行采集。
Q3:为什么传统爬虫越来越难抓取 Shopify 数据?
随着 Shopify 商家大量采用 React、Vue、Next.js 等前端框架,以及 Cloudflare、DataDome 等反爬系统的普及,传统依赖 XPath 或 CSS Selector 的爬虫更容易失效。页面结构一旦调整,就可能导致解析规则失效,因此维护成本越来越高。
Q4:AI 网页抓取相比传统爬虫有哪些优势?
AI 网页抓取能够基于语义理解页面内容,而不仅仅依赖固定标签定位。它可以自动识别商品名称、价格、SKU、规格等信息,并在页面布局发生变化时保持较好的适应能力。同时还能完成数据清洗和结构化输出,大幅降低开发和维护成本。
Q5:大规模抓取 Shopify 商品数据时为什么需要住宅代理 IP?
当采集规模扩大到数百甚至上千个 Shopify 店铺时,频繁访问容易触发 Cloudflare 等风控系统,导致出现 403、验证码或 IP 封禁。住宅代理 IP 能模拟真实用户网络环境,配合 IP 轮换和随机访问策略,可有效提升 Shopify 数据抓取的稳定性和成功率。
随着 AI 技术的发展,Shopify 商品数据采集正从传统规则驱动逐步转向智能化抓取。相比传统爬虫,AI 能更好地理解页面内容,自动完成数据提取与结构化处理,同时降低开发和维护成本。
对于跨境电商团队而言,结合 Shopify 原生接口、浏览器自动化工具以及稳定的代理网络,不仅能够提升数据采集效率,还能增强规模化抓取的稳定性,为选品调研、竞品分析和市场洞察提供更可靠的数据支持。
 微信公众号
微信公众号