





产品分享社区
声明:网站上的服务均为第三方提供,请用户注意甄别服务质量
Naver,韩国最大的搜索引擎和科技巨头,是韩国数字生活的核心。从电子商务到数字支付、博客和新闻消息,它在多个领域拥有庞大的用户群体与数据。可以说,在韩国,真正的流量入口不是 Amazon,而是Naver。
如果你想稳定、规模化获取 Naver 商店数据,就必须用更系统的方法。本文将带你拆解实战策略,帮助你在合规前提下,快速以最小成本抓取Naver平台的数据,以更好的做出决策。
如果你做的是韩国跨境市场,但数据来源仍停留在 Google、Amazon 或全球工具,那么你看到的只是“外围信息”,而不是本地真实消费信号。抓取 Naver,本质上是获取韩国本土数据语境。在韩国,Naver是:
通过抓取 Naver 的搜索结果、商品信息、博客、论坛和新闻内容,能帮助卖家:
换句话说,Naver 数据抓取不仅能支撑选品、定价和推广策略,更能让跨境卖家在竞争激烈的韩国市场中保持优势。
Naver将内容组织成多个专门板块,每个板块都有独特的 URL 模式和 DOM 结构,抓取的时候需要提前想清楚。主要板块包括:
在抓取数据之前,必须提前规划抓取策略,明确要获取的内容类型以及对应的解析方法,才能高效提取有价值的数据。
Naver 页面结构复杂,同时包含大量韩文内容,因此对请求稳定性和解析能力都有一定要求,需要先搭建一个基础的Python抓取环境。
1. 安装常用的抓取依赖库:

这些库分别承担不同职责:
2. 导入基础模块

3. 韩文文本与编码预处理
虽然 Python 3.x 默认支持 Unicode,但在抓取 Naver 时仍需注意:
如果不提前处理这些问题,后续数据存储、关键词匹配和情感分析都会受到影响。
4. 风控与访问节奏控制
跨境卖家在批量抓取时,不要忽略请求节奏与IP风控,Naver会根据异常访问行为限制访问。建议使用适合的动态IP或人为操作随机请求间隔来进行访问轮换。
Naver 会根据请求头、语言偏好、连接方式等判断访问来源。如果直接使用默认请求配置,极易被识别为异常流量。因此,我们需要模拟一个“真实的韩国浏览器环境”。
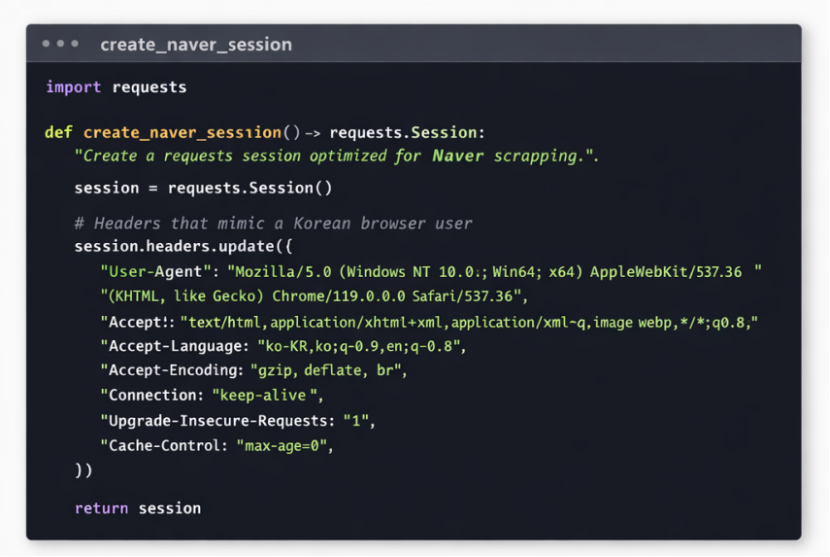
这一步的关键点有两个:
2. 营造安全环境
为了提高稳定性,我们还需要一个带重试逻辑的页面请求函数:
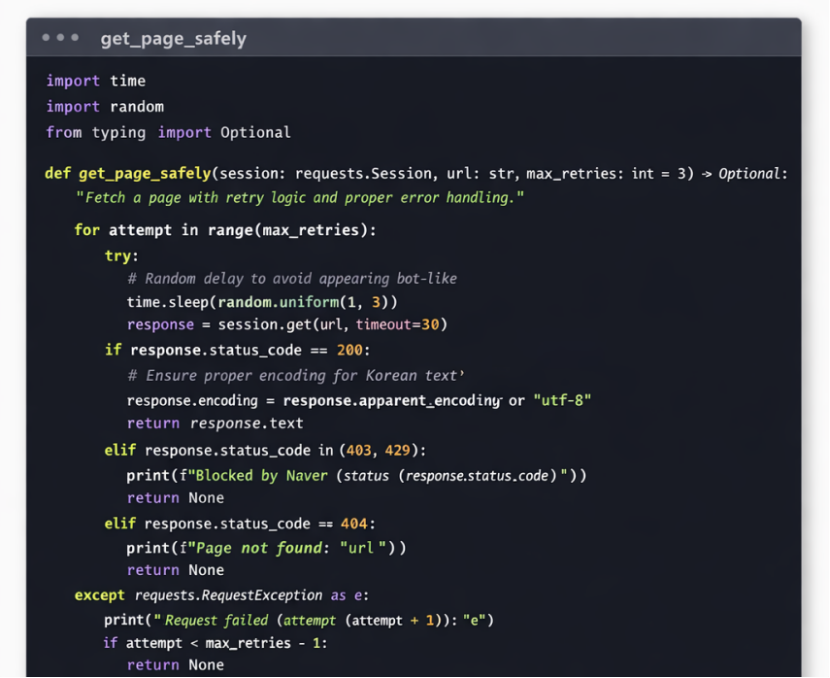
2. 统一数据结构
所有结果都转成统一格式(字典/JSON),方便存数据库或分析。
3. 批量关键词搜索
4. 结果汇总
按关键词分类保存,统计总条数。
1. 建立稳定的会话机制
高成功率的核心在于“像真实用户一样访问”。Naver 会根据访问路径、停留时间、页面跳转逻辑来判断是否为异常流量。如果每次请求都是孤立行为,系统很快会识别异常。
优化方向:
2. 合理控制请求节奏
短时间内大量请求极易触发 429 限速或 403 拒绝访问。相比暴力抓取,更科学的方式是:
IP 是影响成功率的关键因素之一。Naver会分析IP 的地理位置、历史行为和访问模式。如果频繁使用同一 IP 或使用异常数据中心IP,很容易被识别。
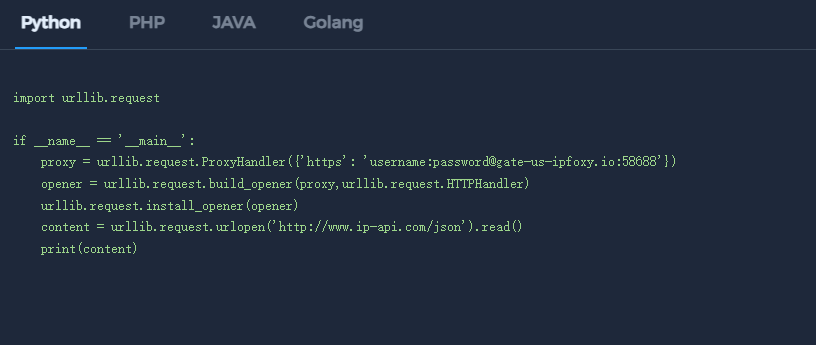
在数据抓取中,通常会接入动态住宅 IP 进行轮换,以降低单 IP 暴露风险。IPFoxy提供的的动态IP代理服务,可以通过API调用和Demo代码接入两种方式应用于数据爬取中,
以下为IPFoxy提供的Python抓取Demo示例:
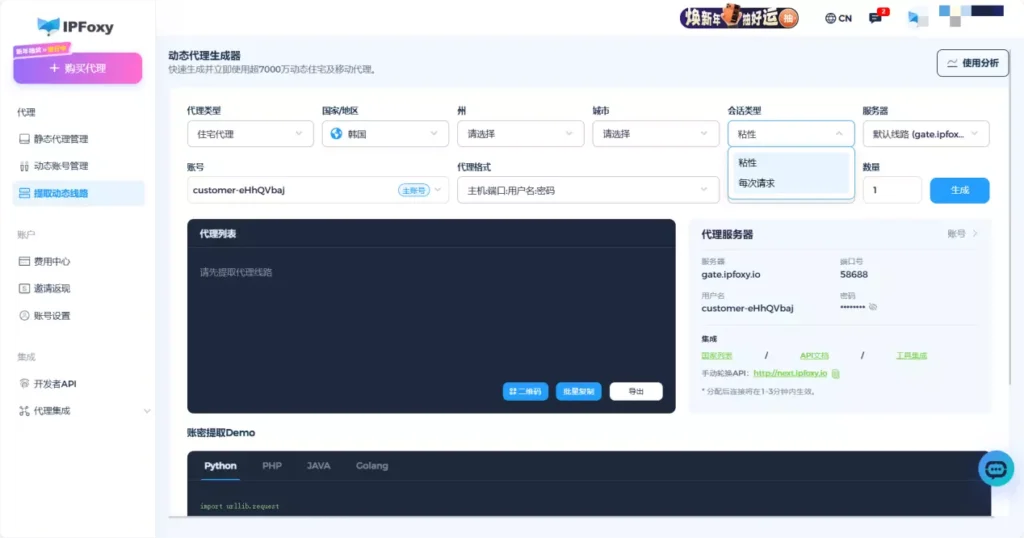
通过动态代理控制面板,可以生成韩国动态住宅/移动IP,支持按请求或按时间自动切换出口 IP。在批量抓取场景下,这种方式更利于维持访问稳定性,同时减少风控触发概率。
为什么我抓取到的Naver数据不完整?
常见原因有三种:页面内容由 JavaScript 动态加载、请求头未正确模拟本地浏览器、页面存在延迟加载或分页机。解决思路是一,检查是否遗漏异步加载内容;二,确保语言优先为韩语;三,验证分页参数规则。
为什么我的抓取程序运行几分钟就被封?
Naver会基于行为模型进行识别,而不仅仅是看访问次数。你有可能是使用固定 IP 长时间高频访问、无会话连续性、无页面停留行为。建议控制IP请求频率、设置随机访问间隔、模拟真实浏览行为、使用动态住宅 IP 轮换等操作来避免风控。
如何提高批量关键词抓取效率?
当关键词数量超过 100 个时,问题就从“能不能抓”变成“如何稳定高效抓”。这里建议策略是可以关键词分批执行、设置任务队列、不同关键词分配不同 IP、并结合动态 IP 轮换机制,来提高抓取效率。
在韩国市场,Naver是流量入口,也是消费趋势的风向标。随着电商规模持续扩大,谁能更早获取本地真实数据,谁就更具竞争优势。稳定抓取Naver商店与内容数据,不只是技术动作,更是市场决策能力的体现。提前布局数据能力,才能在韩国电商竞争中占据主动。
 微信公众号
微信公众号