





产品分享社区
声明:网站上的服务均为第三方提供,请用户注意甄别服务质量
Reddit 是全球访问量最高的论坛社区之一,覆盖从科技、金融到美妆、游戏的几乎所有垂直领域。Reddit用户所进行的情绪表达真实的深度讨论,对于舆情监控、市场调研,或是训练AI模型等等具有极高的参考价值。
然而,尽管 Reddit 数据价值极高,真正稳定地获取这些数据并不容易。许多开发者或运营人员在尝试抓取 Reddit 数据时,往往会遇到请求被限制、IP 被封禁、返回数据不完整等问题。尤其是在进行大规模数据采集或长期运行任务时,Reddit 的风控机制会进一步提高抓取难度。
通过本文,您可以从零开始构建一个稳定、可扩展的 Reddit 数据采集方案。
Reddit 数据爬取(Reddit Data Scraping),简单来说,就是通过自动化程序(爬虫)从 Reddit 平台批量获取公开数据的技术手段。
这些数据包括 Reddit 上丰富的非结构化内容,例如:
通过爬虫,我们可以将这些零散、非结构化的原始信息,清洗并转化为结构化、可存储、可分析的数据集,进而服务于出海营销竞品调研、舆情分析或自动化产品开发等多种场景。
很多开发者遇到数据抓取失败的情况,其实并非技术问题单一导致,而是 Reddit 本身的 风控机制 + 数据结构 + 访问策略 共同造成的。
1.频率限制
当爬虫程序在短时间内向 Reddit 服务器发送大量请求时,系统会识别异常访问行为并触发限制机制,如果超过限制可能会对源 IP 进行临时封禁或限流处理,导致后续请求返回空数据、403 状态码,或出现 429 Too Many Requests 错误页面。
2.IP 风控严格
这是 Reddit 数据抓取失败最常见且最关键的原因之一。Reddit 对访问来源 IP 的真实性和稳定性要求较高,即使使用代理池,如果代理 IP 质量较差或切换策略不合理,同样难以绕过平台风控。例如,数据中心 IP 容易被识别为自动化访问流量;而被多人反复共享代理 IP污染度较高,更容易被平台检测并限制访问。
3.User-Agent 与指纹检测
Reddit 服务器会对 HTTP 请求头及访问特征进行检测,以识别是否为真实用户访问。如果请求中的 User-Agent 显示为常见爬虫标识\缺少浏览器常见字段,请求通常会被识别为非正常访问并受到限制。在更严格的风控环境下,平台还会结合访问行为、请求间隔及浏览器指纹等信息进行综合判断,从而进一步提升封禁概率。
4.API 访问限制严格
Reddit 官方虽然提供 API 接口用于数据访问,但免费调用额度越来越少,也严格限制访问频率和数据范围。对于需要大规模采集数据的场景,API 的速率限制(Rate Limit)很容易成为瓶颈,频繁触发限制后可能导致任务中断或数据缺失。
4.前端动态渲染增加抓取难度
Reddit 新版前端采用 React 等现代前端框架构建,页面主要内容通过 JavaScript 在浏览器端动态加载,而不是直接包含在服务器返回的 HTML 中。这意味着传统的 HTTP 请求工具(如 Python 的 requests)获取到的往往只是基础页面结构,而非完整的帖子与评论数据。为了获取完整内容,通常需要模拟浏览器行为或解析内部 API 请求,这无形中增加了数据抓取的技术复杂度和维护成本。
5.登录墙与权限限制
近年来 Reddit部分内容必须在登录状态下才能访问,这就导致未登录状态下抓取的数据不完整。如果通过批量账号登录进行抓取,则又面临账号被限制或封禁的风险,还可能引发账号关联问题,从而形成账号与 IP 同时受限的连锁反应,进一步增加数据抓取难度。
要稳定抓取 Reddit 数据,你需要应对其反爬机制,主要包括频率限制和IP封锁。结合使用 Python 编程和动态代理 IP 是最有效的解决方案。

Python 拥有丰富的 HTTP 请求库,结合动态代理 IP 可以有效规避上文所述问题。例如,IPFoxy所提供的稳定动态代理IP会隐藏你的真实IP,在每次请求时更换不同IP地址,让你的抓取行为看起来像是来自不同的用户,从而降低被封锁的风险。
1.通过 Python 配置动态代理抓取 Reddit
这里我们将使用 Python 的 requests 库来发送 HTTP 请求,并结合 IPFoxy 提供的代理 IP 进行配置。
步骤一:安装必要的库
首先,确保你的 Python 环境中安装了 requests 库。
pip install requests
步骤二:Python配置动态代理
在爬取 Reddit 时,如果请求频率过高或 IP 被风控,很容易触发限制或封禁。配置动态代理(住宅代理) 可以有效降低被封风险,让爬虫稳定运行。
下面以 IPFoxy 动态住宅代理 为例,演示如何在 Python 中配置并使用代理。
通过IPFoxy获取【动态住宅代理】,分别配置州城市、协议类型、会话轮换类型、代理格式等信息,获取到可用于链接的代理连接信息。
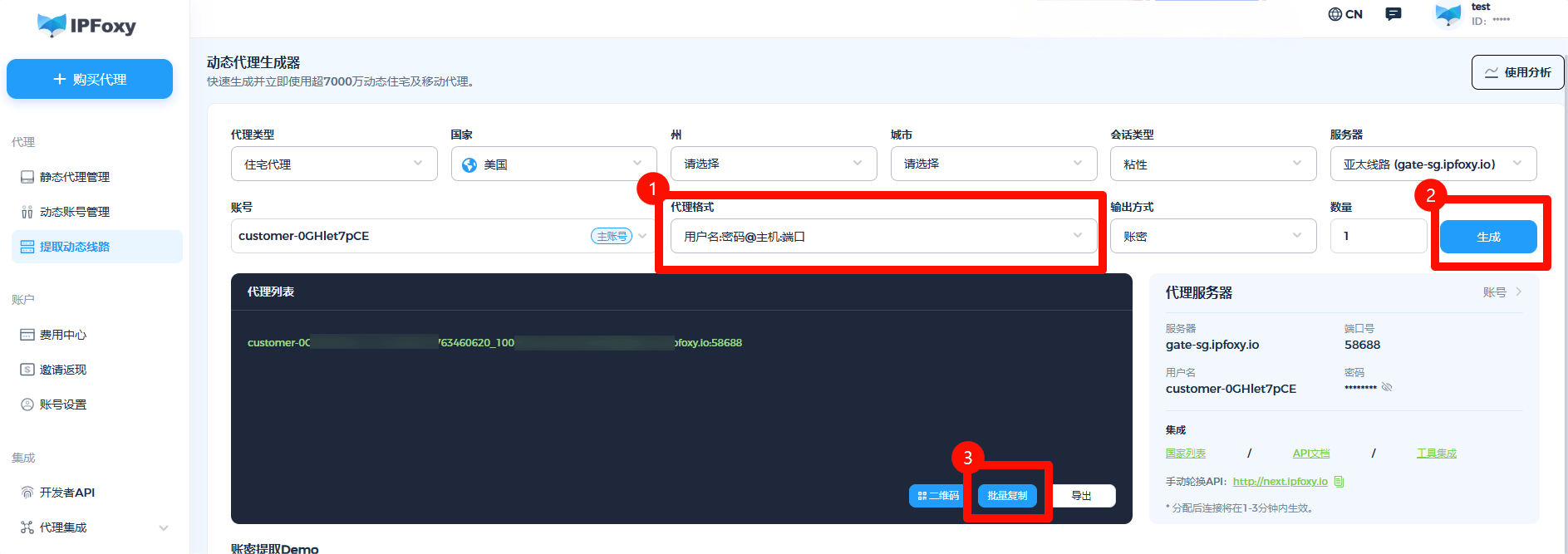
2、在Python中配置代理
将刚刚在IPFoxy复制的代理连接信息粘贴到配置以下配置示例代码中,如代理连接信息是:username:password@gate-us-ipfoxy.io:58688,那么配置代码示例如下:
import urllib.request
if __name__ == '__main__':
proxy = urllib.request.ProxyHandler({
'https': 'username:password@gate-us-ipfoxy.io:58688',
'http': 'username:password@gate-us-ipfoxy.io:58688',
})
opener = urllib.request.build_opener(proxy,urllib.request.HTTPHandler)
urllib.request.install_opener(opener)
content = urllib.request.urlopen('http://www.ip-api.com/json').read()
print(content)
这时,直醒行代码就可以从日志看到出口IP改变,此时信息配置成功,可以进行下一步操作。

步骤三:Reddit抓取的Python 代码示例
以下是一个使用 requests 库和 IPFoxy 动态代理抓取 Reddit 页面内容的示例,可以参考:
import requests
import time
import random
# ============================================================
# IPFoxy 代理配置 —— 替换为你的实际信息
# ============================================================
IPFOXY_USERNAME = "your_ipfoxy_username"
IPFOXY_PASSWORD = "your_ipfoxy_password"
IPFOXY_PROXY_HOST = "gate.ipfoxy.com"
IPFOXY_PROXY_PORT = "10000"
# ============================================================
# 目标 URL(使用 .json 接口,直接返回结构化数据,无需解析 HTML)
# 修改 r/popular 为你想抓取的版块名称
# ============================================================
TARGET_SUBREDDIT = "popular"
TARGET_URL = f"https://www.reddit.com/r/{TARGET_SUBREDDIT}.json"
# 每页最多返回的帖子数(Reddit 最大支持 100)
LIMIT = 25
# 抓取轮次
ROUNDS = 3
def get_proxies():
"""构造 IPFoxy 动态代理配置"""
proxy_url = (
f"http://{IPFOXY_USERNAME}:{IPFOXY_PASSWORD}"
f"@{IPFOXY_PROXY_HOST}:{IPFOXY_PROXY_PORT}"
)
return {"http": proxy_url, "https": proxy_url}
def get_headers():
"""随机返回一组仿真浏览器请求头"""
user_agents = [
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:125.0) Gecko/20100101 Firefox/125.0",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36",
]
return {
"User-Agent": random.choice(user_agents),
"Accept": "application/json, text/javascript, */*; q=0.01",
"Accept-Language": "en-US,en;q=0.9",
"Accept-Encoding": "gzip, deflate, br",
"Connection": "keep-alive",
"Referer": "https://www.reddit.com/",
}
def fetch_reddit_json(url, params=None):
"""
通过动态代理请求 Reddit JSON 接口。
返回解析后的 dict,失败返回 None。
"""
proxies = get_proxies()
headers = get_headers()
try:
response = requests.get(
url,
headers=headers,
proxies=proxies,
params=params,
timeout=15,
)
response.raise_for_status()
return response.json()
except requests.exceptions.ProxyError as e:
print(f" [代理错误] 代理连接失败,请检查账号信息或代理地址: {e}")
except requests.exceptions.Timeout:
print(" [超时] 请求超时,当前代理响应过慢")
except requests.exceptions.HTTPError as e:
print(f" [HTTP错误] 状态码 {e.response.status_code},可能被限流或封禁")
except requests.exceptions.RequestException as e:
print(f" [请求异常] {e}")
except ValueError:
print(" [解析错误] 返回内容不是合法 JSON,可能触发了 CAPTCHA 或被重定向")
return None
def parse_posts(data):
"""从 Reddit JSON 响应中提取帖子列表"""
posts = []
try:
children = data["data"]["children"]
for item in children:
post = item["data"]
posts.append({
"title": post.get("title", ""),
"subreddit": post.get("subreddit_name_prefixed", ""),
"score": post.get("score", 0),
"comments": post.get("num_comments", 0),
"url": "https://www.reddit.com" + post.get("permalink", ""),
"author": post.get("author", ""),
"created_utc": post.get("created_utc", 0),
})
except (KeyError, TypeError) as e:
print(f" [解析错误] 数据结构异常: {e}")
return posts
def main():
print(f"开始抓取 r/{TARGET_SUBREDDIT},共 {ROUNDS} 轮\n")
all_posts = []
after = None # Reddit 分页游标
for i in range(ROUNDS):
print(f"--- 第 {i + 1} 轮 ---")
params = {"limit": LIMIT}
if after:
params["after"] = after # 翻页:传入上一页的游标
data = fetch_reddit_json(TARGET_URL, params=params)
if data is None:
print(" 本轮抓取失败,跳过\n")
time.sleep(random.randint(8, 15))
continue
posts = parse_posts(data)
after = data.get("data", {}).get("after") # 更新翻页游标
if not posts:
print(" 未获取到帖子,可能已到末页\n")
break
all_posts.extend(posts)
print(f" 本轮获取 {len(posts)} 条,累计 {len(all_posts)} 条")
for p in posts:
print(f" [{p['score']:>6} 分] {p['title'][:60]}")
print()
# 模拟真实用户行为,随机暂停
if i < ROUNDS - 1:
sleep_time = random.randint(6, 12)
print(f" 等待 {sleep_time} 秒后继续...\n")
time.sleep(sleep_time)
print(f"\n抓取完成,共获取 {len(all_posts)} 条帖子。")
return all_posts
if __name__ == "__main__":
main()
2. 提高抓取稳定性的要点
除了使用动态代理,还有一些额外信息可以帮助你更稳定地抓取Reddit:
1.抓取 Reddit 数据时,使用什么类型的代理更合适?
更推荐使用动态住宅代理IP,稳定性高、被封概更低,更接近真实用户网络环境,适合长期运行爬虫任务。
2.如何提高 Reddit 爬虫的稳定性?
除了配合动态住宅IP,建议避免高频访问,添加请求间隔,通过模拟真实用户访问行为,降低被识别风险。
3.抓取 Reddit 数据是否合法?
通常情况下,抓取 Reddit 上 公开且无需登录访问的数据 是可行的,例如公开帖子、评论和互动数据。
通过合理的 Python 爬虫逻辑、稳定的请求策略以及高质量代理环境,可以显著提升 Reddit 数据抓取的成功率与稳定性。在大规模或长期采集场景下,使用住宅代理,有助于降低封禁风险并保证数据连续性,从而构建更加稳定、高效的 Reddit 数据采集方案。
 微信公众号
微信公众号