








产品分享社区
声明:网站上的服务均为第三方提供,请用户注意甄别服务质量
在数据驱动的内容生态中,YouTube数据抓取已成为开发者和运营人员的重要工具。无论是视频分析、关键词研究,还是竞品监控,都离不开高效的数据采集能力。
本指南将从基础概念到实战开发,系统讲解如何使用 Python + Playwright 构建稳定的 YouTube 爬虫,包括数据获取方式、代码实现以及防封策略,帮助你快速搭建可用的数据抓取方案。
在2026年,随着视频内容竞争不断加剧,YouTube已经成为数据分析、内容研究和营销决策的重要来源。越来越多开发者和运营团队开始关注YouTube数据抓取(YouTube Data Scraping),用于获取视频、评论、频道等关键数据。
所谓YouTube数据抓取,是指通过程序自动访问YouTube网页或官方接口(API),批量提取结构化数据的过程。而在实际开发中,最常用的实现方式就是基于 Python 的YouTube爬虫。
与手动浏览相比,爬虫可以在短时间内完成大规模数据采集,例如:
这使得YouTube数据抓取被广泛应用于内容分析、竞品研究以及自动化数据处理等场景。
不过,需要注意的是,随着平台风控不断加强,单纯依赖基础爬虫已经很难稳定获取数据。如何在保证效率的同时避免被封,成为YouTube数据抓取中必须解决的核心问题。
在进行YouTube数据抓取之前,首先需要明确可以采集哪些数据类型。不同的数据对应不同的应用场景,是构建Python YouTube爬虫时的重要基础。通常来说,YouTube数据采集主要分为以下三类:
通过抓取视频数据,可以用于内容分析、爆款视频挖掘以及关键词研究。视频数据通常包括:
通过批量抓取评论数据,可以进行舆情分析、用户需求挖掘以及情绪分析。评论数据通常包括:
频道数据可以帮助你评估账号表现、制定内容策略或进行竞品分析,频道数据主要包括:

在实际开发Python YouTube爬虫时,常见的数据获取方式主要有两种:通过官方API获取数据,以及通过爬虫直接抓取页面数据,可以根据需求进行选择。
YouTube官方提供了Data API,允许开发者通过接口获取平台上的部分数据。这是一种较为规范的YouTube数据采集方式。
优点:
缺点:
因此,API更适合轻量级或合规要求较高的项目。
相比API,直接通过爬虫抓取页面数据是更灵活的方式。
常见实现方式包括:
优点:
缺点:
在实际选择时,可以通过以下对比来判断哪种方式更适合你的需求:
| 对比项 | YouTube Data API | Python爬虫抓取 |
| 数据来源 | 官方接口 | 页面HTML / 接口数据 |
| 数据完整性 | 较有限 | 更全面 |
| 开发难度 | 较低 | 中等偏高 |
| 稳定性 | 高 | 依赖策略 |
| 是否易被封 | 不易 | 容易触发反爬 |
| 请求限制 | 有配额限制 | 无固定限制 |
| 灵活性 | 较低 | 高 |
| 适用场景 | 轻量数据获取 | 大规模数据采集 |
在了解了基本原理之后,接下来通过一个更稳定的方案,演示如何使用 Playwright + Python 实现YouTube数据抓取。
相比 requests 和 Selenium,Playwright 可以模拟真实浏览器环境,有效应对 YouTube 的动态渲染和反爬机制,更适合实际项目使用。

建议:
headless=True 表示无头模式(适合服务器运行)wait_for_selector 替代 networkidle,在 YouTube 页面更稳定requests,这里获取的是渲染后的完整DOM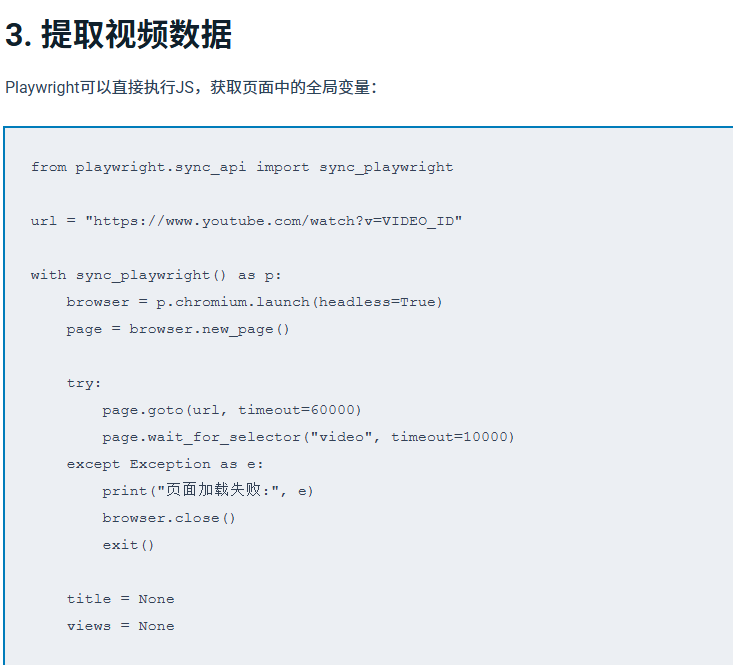
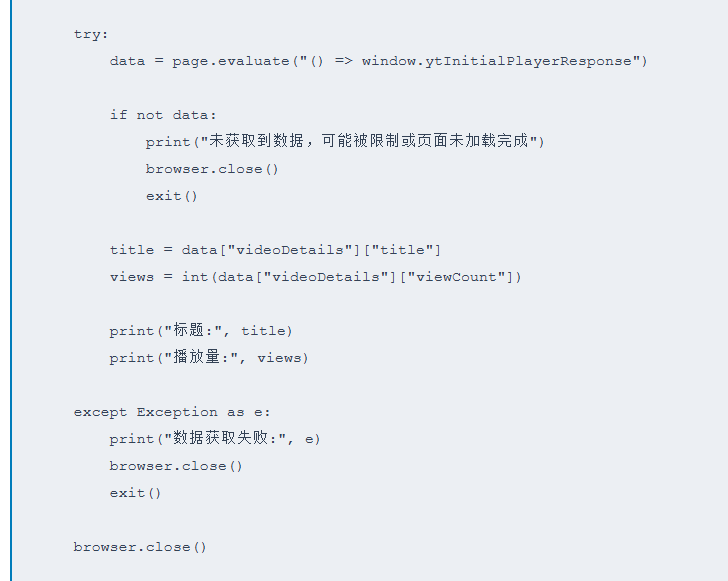
说明:
window.ytInitialPlayerResponse,比正则解析更稳定
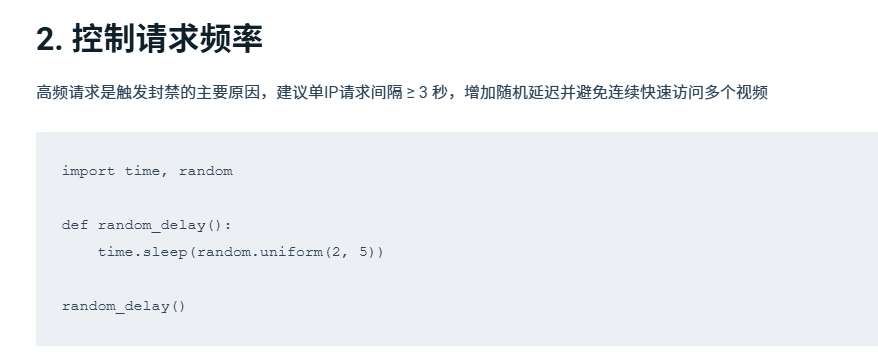
抓取 YouTube 数据时,常见问题是 IP封禁、验证码和数据不全。稳定抓取的核心是:控制请求特征 + 分散来源 + 模拟真实环境。
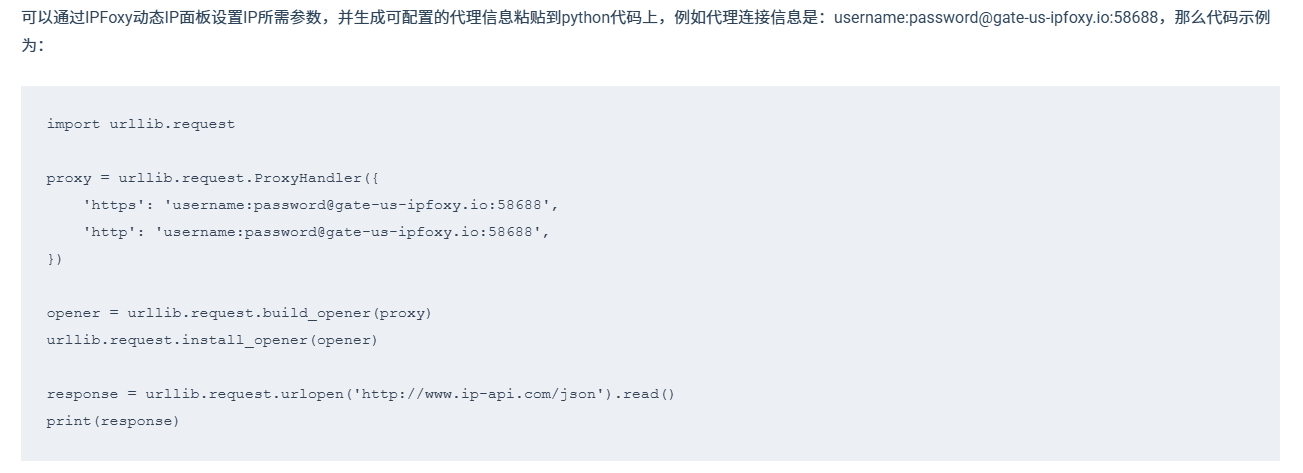
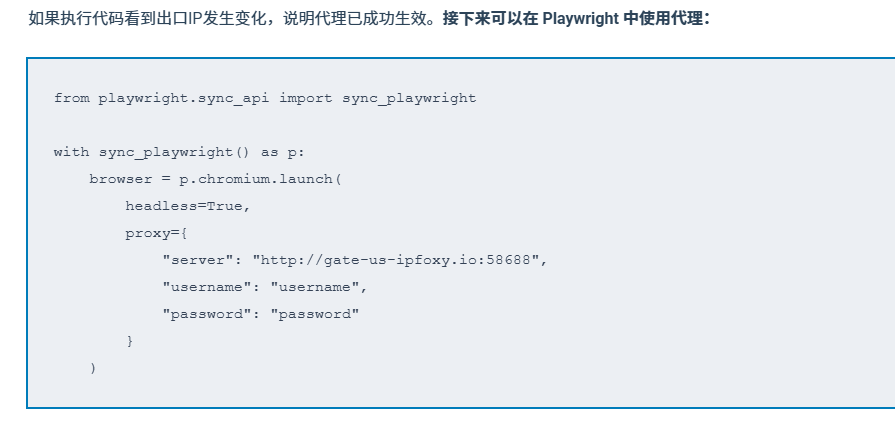
YouTube 会基于 IP行为 进行风控,因此使用代理IP是稳定抓取的关键。
推荐使用高质量的动态住宅代理,如果IP重复率高或被滥用,很容易触发限制。因此,通常会选择像 IPFoxy 这类提供优质动态住宅代理服务,通过广泛且干净的IP池子配合灵活的轮换机制,来降低请求被识别的概率。同时可以根据不同任务设置出口地区或切换策略,适配不同的数据抓取需求。
以下是IPFoxy代理IP示例(Python)
可以通过IPFoxy动态代理生成器配置IP轮换策略,可以根据不同抓取场景灵活配置:

仅使用代理还不够,YouTube还会检测浏览器行为。
建议设置 User-Agent,等待关键元素加载并模拟用户操作(滚动/停留),避免使用纯HTTP请求(如requests)进行大规模抓取
page = browser.new_page(
user_agent="Mozilla/5.0 (Windows NT 10.0; Win64; x64)"
)
page.goto(url)
page.wait_for_selector("video")很多人可能会忽略采集规模,其实不同规模需要不同方案:
| 规模 | 推荐方案 |
| <100条 | Playwright + 单IP |
| 100~1万 | Playwright + 动态代理 |
| 1万+ | 分布式 + IP池 + 调度系统 |
Q:Playwright 和 Selenium 哪个更适合 YouTube?
Playwright 更适合动态网站抓取,支持 JavaScript 渲染和真实浏览器环境,抗封能力较强;Selenium 更适合传统自动化测试。
Q:可以不使用代理直接抓取吗?
小规模测试可以,但中到大规模抓取几乎不可行。代理能隐藏真实IP,降低被封概率。
Q:爬虫数据保存有什么推荐方式?
JSON 或 CSV 都可,JSON 更适合嵌套数据结构,CSV 更适合表格化分析。保存前建议检查数据完整性。
通过本文,你已经掌握了从基础原理到实战代码的完整 YouTube数据抓取流程,并了解了在实际项目中如何通过代理IP、请求控制和浏览器模拟来提升稳定性。
如果你需要进一步扩展,可以继续深入评论抓取、搜索页采集或分布式爬虫方案。合理选择技术方案并优化抓取策略,才能在保证稳定性的前提下,实现长期可用的数据采集系统。
 微信公众号
微信公众号