






产品分享社区
声明:网站上的服务均为第三方提供,请用户注意甄别服务质量
在数字化时代,视觉内容的获取变得愈加重要,尤其是在社交平台如Pinterest上,海量的高质量图片为用户和品牌提供了巨大的数据价值。随着Pinterest持续优化反爬虫机制,批量抓取Pinterest图片成为了数据分析和内容收集的重要技能。本文将探讨如何高效地抓取大量Pinterest图片,解决常见的技术难题,帮助你提高抓取成功率和效率。
Pinterest作为全球领先的视觉发现引擎,拥有超过4.5亿月活用户,批量抓取Pinterest图片可以为用户提供以下优势:
在开始实战之前,我们需要了解Pinterest设置的重重技术壁垒:
Pinterest是典型的单页应用,图片等内容通过JavaScript加载。传统的requests+BeautifulSoup组合无法获取完整内容,需借助浏览器自动化工具模拟真实用户行为。
Pinterest采用多层反爬机制:
针对上述挑战,目前主流的技术方案有以下几种:
对于大多数开发者来说,站在巨人的肩膀上是最佳选择。目前GitHub上有两个成熟的Pinterest爬虫库,经过实测,它们在2026年的Pinterest版本上依然表现良好。
无论你选择使用pinterest-dl进行快速批量下载,还是基于Playwright构建原生自动化脚本,IPFoxy提供的的动态IP代理,可以通过API调用和Demo代码接入两种方式应用于数据爬取中。
例如,如果您需要在您的脚本中接入IPFoxy动态HTTP代理,可以应用以下Demo:
import urllib.request
if __name__ == '__main__':
proxy = urllib.request.ProxyHandler({'https': 'username:password@gate-us-ipfoxy.io:58688'})
opener = urllib.request.build_opener(proxy,urllib.request.HTTPHandler)
urllib.request.install_opener(opener)
content = urllib.request.urlopen('http://www.ip-api.com/json').read()
print(content)
当开源库无法满足特定需求时,直接使用Playwright进行浏览器自动化是更灵活的选择。这种方法可以完全控制抓取过程,实现精细化操作。
核心思路:Pinterest是单页应用,数据通过XHR请求动态加载。与其解析DOM,不如直接监听网络响应,捕获包含图片URL的JSON数据。
在实际运行中,经常会遇到验证码和滚动加载失败的情况。以下是增强版的代码,加入反检测和验证码处理机制:
class AdvancedScraper:
async def stealth_init(self):
stealth_js = """
Object.defineProperty(navigator, 'webdriver', {get: () => undefined});
Object.defineProperty(navigator, 'languages', {get: () => ['en-US', 'en']});
"""
self.playwright = await async_playwright().start()
self.browser = await self.playwright.chromium.launch(
args=['--disable-blink-features=AutomationControlled']
)
self.context = await self.browser.new_context()
await self.context.add_init_script(stealth_js)
self.page = await self.context.new_page()
对于需要长期稳定运行、大规模采集的场景,商业化API是更明智的选择。这类服务已经处理好了反爬虫、IP轮换、数据格式化等问题。
这是爬虫能否长期稳定运行的关键,以下是经过验证的优化策略:
数据中心IP和公共VPN的IP段已被Pinterest列入黑名单,Pinterest的风控系统会检测IP纯净度,住宅IP更接近真实用户,被识别为非正常用户的概率更低。在Pinterest批量图片抓取实战中我们使用IPFoxy代理辅助规避爬虫限制:
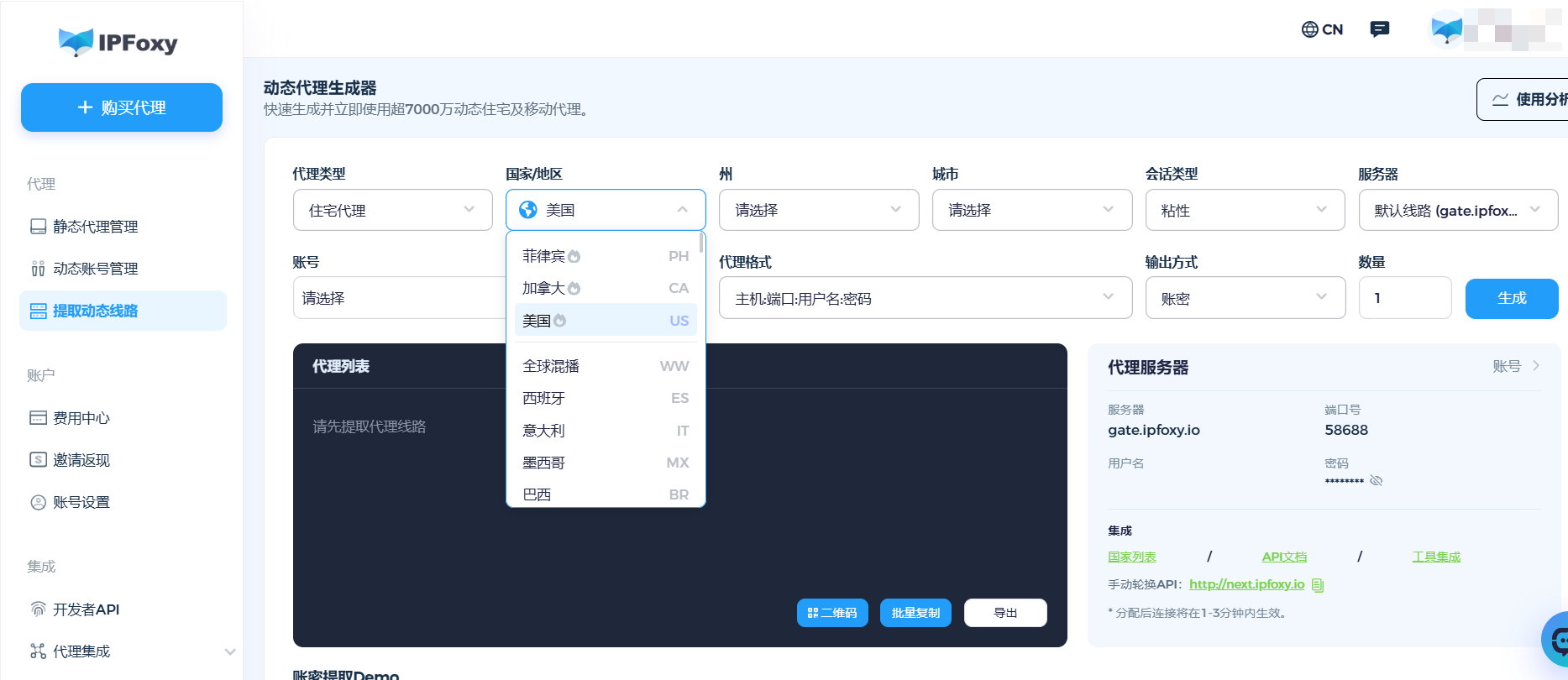
当Pinterest图片采集从测试阶段的几十张扩展到生产环境的上万张时,最大的瓶颈往往不在代码逻辑,而在于IP的稳定性与环境的纯净度。
仅更换IP是不够的,Pinterest还会追踪浏览器指纹。对于多账号或高频采集场景,建议使用指纹浏览器,为每个抓取任务生成独立的浏览器环境,从而避免多账号、多任务之间的指纹关联。
遵循黄金法则:模仿人类操作节奏
# pinterest-scrapper中的合理配置示例
scraper.scrape_search(
query="home decor",
max_pins=100,
max_scrolls=20, # 限制单次滚动次数
scroll_pause=2.0, # 每次滚动后暂停2秒
)
通过复用登录后的Cookies,可以免去重复登录,同时降低风控概率:
# 登录并保存cookies
pinterest-dl login -o cookies.json
# 后续抓取自动使用保存的cookies
pinterest-dl scrape <URL> --cookies cookies.json
Q1:批量下载Pinterest图片是否合法?
A:需注意以下法律边界:确认版权:大多数图片由创作者拥有,下载前应假设有版权保护合理使用:编辑或改变性使用可能符合合理使用原则,但商业用途风险较高建议做法:追溯来源、保留归属信息、不删除水印、不用于侵权用途
Q2:频繁下载一定会被封号吗?
A:不一定,但高频异常行为封号风险极高。触发封禁的关键因素包括:请求频率过快、IP异常、行为模式非人类、多账号共用同一环境。采用本文推荐的IP代理+合理频率+指纹隔离策略,可大幅降低风险。
Q3:如何抓取图片的高清版本?
A:通过解析Pinterest页面的图片URL,获取最大尺寸的图片链接。
在2026年,开发者不仅要面对技术挑战,还要学会如何规避反爬虫系统,确保抓取过程的安全与高效。通过使用高质量的代理IP、控制请求频率、采用指纹隔离技术等优化策略,你可以大幅提升Pinterest图片抓取的成功率和效率。
记住,批量抓取Pinterest图片的过程不仅仅是技术上的挑战,更是如何在遵守法律和平台政策的前提下,实现数据获取的平衡。
 微信公众号
微信公众号