





产品分享社区
声明:网站上的服务均为第三方提供,请用户注意甄别服务质量
在全球跨境电商和 AI 数据分析的时代,谁能快速理解海外用户需求,谁就能抢占市场先机。Quora 作为一个高质量的问答社区,不仅汇集了大量真实用户提问和讨论,还经常出现在 Google 搜索结果的前列。对跨境卖家来说,它是获取自然流量和市场洞察的宝库;对 AI 从业者来说,它是训练模型、构建垂直知识库的丰富数据源。
本文将带你系统了解如何抓取 Quora 数据,帮助跨境卖家精准洞察海外买家需求,同时为 AI 模型训练和知识库构建提供高质量结构化数据。
很多跨境卖家和 AI 从业者在工作中会遇到海外买家需求难以精准把握、缺乏可靠海外数据等问题。Quora作为国外最大的知识问答网站,其问答内容专业且高质量覆盖各种产品、行业和使用场景。
在开始抓取 Quora 问答内容之前,需要先搭建一个稳定、可控的爬取环境,核心目标是:模拟真实用户行为 + 处理动态内容 + 降低反爬风险
Python安装:Python 版本建议 3.10 及以上+ 确保本地或服务器环境已正确安装
Python库安装:
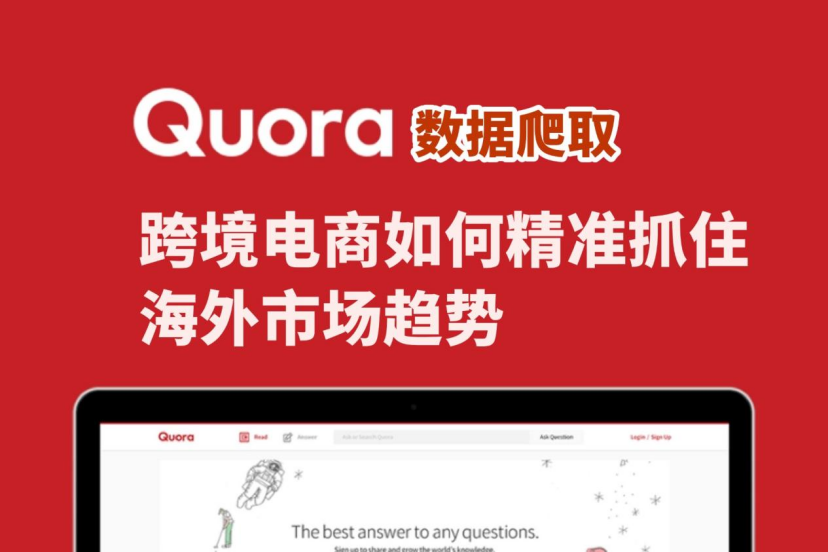
在写代码之前,必须先搞清楚 Quora 的内容是如何组织的,以便识别包含问答数据的关键。
对应div class:div.q-text.qu-dynamicFontSize--regular_title
对应div class:div.q-box.spacing_log_answer_content.puppeteer_test_answer_content
对应span class:span.q-text.qu-whiteSpace--nowrap...
对应div class:div.q-box.dom_annotate_ad_promoted_answer
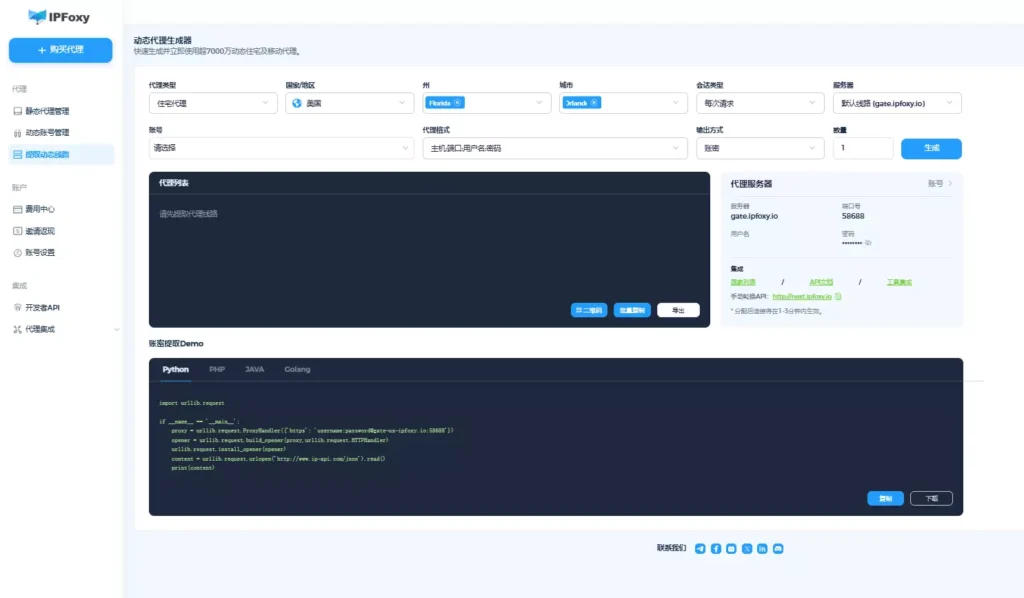
通过代理访问 Quora,避免被封或限制,确保抓取稳定。动态住宅代理可以让请求看起来像真实用户在用浏览器访问,并支持按时间轮换IP从而躲掉反爬限制。我们测试了IPFoxy动态代理池,其质量与功能优势在此类场景中表现明显:
Q1:我为什么要抓取 Quora 的数据?
Quora 汇集了大量高质量的问答内容,覆盖各种产品、行业和使用场景。抓取这些数据可以帮助跨境卖家洞察海外买家痛点、优化产品策略、提升 SEO 排名,也能为 AI 模型训练或构建知识库提供可靠的结构化数据,让分析和决策更精准高效
Q2:Quora 会阻止网页抓取吗?
是的,Quora 会检测异常访问行为,比如频繁刷新、快速翻页或同一 IP 短时间访问大量页面。这些行为会触发反爬机制,导致验证码、访问限制甚至账号封禁。合理使用代理、模拟真实浏览行为和控制访问频率可以有效绕过这些限
Q3:为什么数据爬虫一定要添加代理?
在抓取像 Quora 这样的大流量网站时,如果每次请求都来自同一个 IP,网站很容易判断这是自动化行为,从而限制访问甚至封禁账号。添加代理可以模拟不同用户访问,使抓取更稳定、更安全,同时减少被风控干扰的风
抓取 Quora 数据可以帮助你更好地了解海外市场和用户需求,无论是跨境电商还是 AI 数据分析都能从中获益。把数据整理和分析后,你可以发现热门问题、用户痛点,优化产品策略和内容布局,也能构建高质量的知识库,提高 AI 模型的专业性和准确性。掌握方法后,Quora 的问答数据就能真正成为你的决策助手,让业务和项目更高效、更精准、更有竞争力。
 微信公众号
微信公众号