





产品分享社区
声明:网站上的服务均为第三方提供,请用户注意甄别服务质量
Airbnb(爱彼迎)是全球知名的短期租赁和体验平台。通过网页爬虫技术,我们可以从房源页面中自动采集数据,挖掘平台本身不直接提供的市场信息,但可惜的是Airbnb的抓取难度明显高于普通网站。
本文将从实际可落地的角度出发,系统讲解如何使用 Python 构建一个Airbnb 的爬虫,帮助你在保证稳定性的前提下,高效抓取 Airbnb 房源数据。

在 AI 旅行助手和旅游科技快速发展的背景下,高质量、真实世界的短租数据是训练智能 Agent 和多场景 AI 模型的关键资源。抓取 Airbnb 数据可以在以下三个方向实现落地应用:
抓取 Airbnb 的价格、入住情况和房源信息,AI 可以学会:
适用场景:
结合 Airbnb 和其他平台数据,AI 可以进行:
适用场景:
抓取真实的房源和景点数据,可以训练 AI 生成创意内容:
适用场景:
抓取 Airbnb 并不是简单发送几次 HTTP 请求就能完成的,平台在数据保护方面做了大量工作:
1、 强反爬机制
Airbnb 页面高度依赖 JavaScript 渲染,很多核心内容在浏览器执行后才会出现。平台会通过行为分析、IP 来源、访问频率等方式识别自动化请求,常见拦截方式包括 IP 限制和验证码。
2、 页面结构频繁变动
HTML 结构、类名以及内部接口经常调整,稍不注意就会导致原有爬虫失效,需要持续维护。
3、 IP 访问限制
即使请求成功,Airbnb 也会限制单个 IP 在一定时间内的访问次数。如果策略不当,容易出现数据不完整甚至账号/IP 被封。
目前抓取 Airbnb 数据主要有两种思路:使用第三方数据接口和自己编写爬虫脚本。本文重点介绍如何自行构建 Python 爬虫。如果你具备一定编程基础,自建爬虫可以完全掌控数据采集逻辑和抓取范围。
常用工具包括:
只要持续跟进 Airbnb 的页面变化,这类爬虫可以从小规模研究扩展到长期稳定的数据采集流程。虽然比现成工具更费力,但胜在灵活、可控、可定制。
下面我们将构建一个基于 Playwright 的 Airbnb 爬虫,支持自动翻页,并加入基础的反检测策略,确保抓取过程更稳定。
在开始之前,需要完成以下准备工作:
1、安装 Python & Playwright
建议 Python 3.7 及以上版本,可在终端中检查版本。Playwright 用于浏览器自动化,需要额外下载浏览器内核(Chromium / Firefox / WebKit)。
2、 内置块
脚本主要使用 Python 内置模块(如 csv、time、re),无需额外安装。
3、配置住宅代理
Airbnb 对访问频率和 IP 来源非常敏感,使用住宅代理可以显著降低被封风险。比较多人常用的是IPFoxy 的动态住宅代理,它可以高频自动轮转来规避反爬机制。IPFoxy能提供:
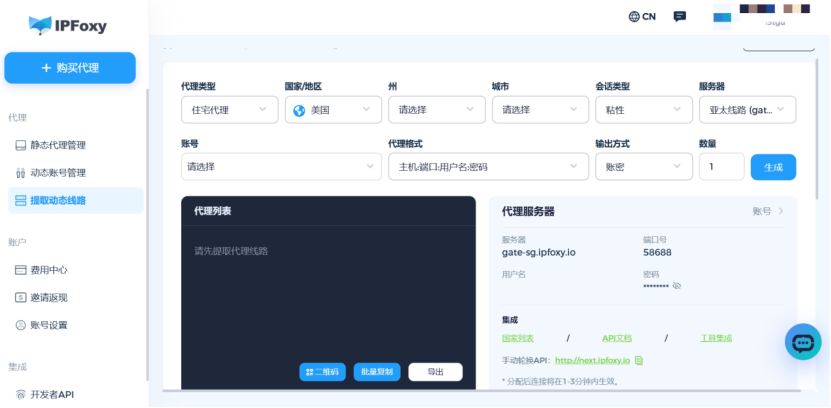
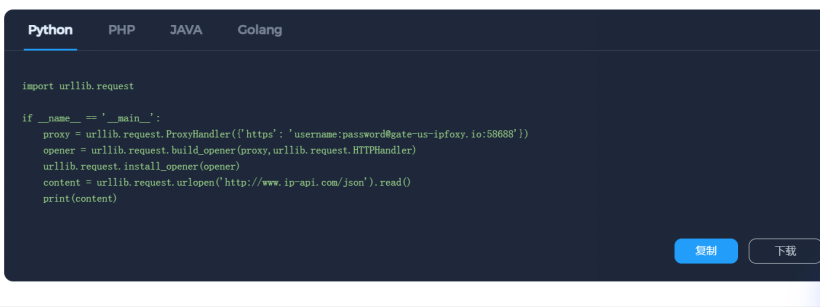
在正式编写爬虫之前,必须先在浏览器中确认数据最终是如何渲染和存储的。
操作步骤如下:
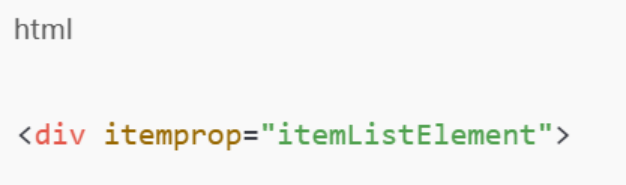
这个容器可以视为 单个房源的“根节点”,后续所有数据提取都会围绕它展开。
在 itemListElement 容器内部,可以找到以下关键数据:
在实际爬虫中,会使用 Playwright 的定位系统 来锁定上述结构:
为避免重复抓取,爬虫会从房源 URL 中提取 房源 ID(room_id),作为唯一标识,用于判断是否已经采集过该房源。
整个爬虫采用面向对象的方式设计,核心围绕一个类:AirbnbScraper,便于维护和扩展。核心构建:
1、列表容器:extract_listing_data()
2、 翻页逻辑:scrape_airbnb
3、 反检测策略
为降低被封风险,爬虫包含以下措施:
抓取完成后,数据会被保存为结构清晰的 CSV 文件,方便后续分析和处理。
save_to_csv() 方法会导出房源的标题、描述、评分、评论数量、价格和房源链接等核心字段,同时排除仅用于去重的内部房源 ID,保证数据干净、可用。
保存完成后,主程序会在终端中打印部分抓取结果的预览,用于快速确认数据是否被正确采集。
本文从实际需求出发,完整介绍了 Airbnb 房源数据抓取的思路与实现流程,包括页面结构定位、Playwright 渲染、基础反检测策略以及数据保存方式。通过合理的工具选择和抓取策略,可以在保证稳定性的前提下获取结构化房源数据。该方案具备良好的扩展性,适合用于持续监测价格变化、市场趋势分析或后续更深入的数据研究。
 微信公众号
微信公众号